With the growing demands of LLM inference, performance has never been more critical. The NVIDIA RTX 5090 brings a new level of compute capability, exceeding expectations and outperforming certain dedicated data center solutions.
Benchmark Showdown: RTX 5090 vs. Professional & Data Center GPUs
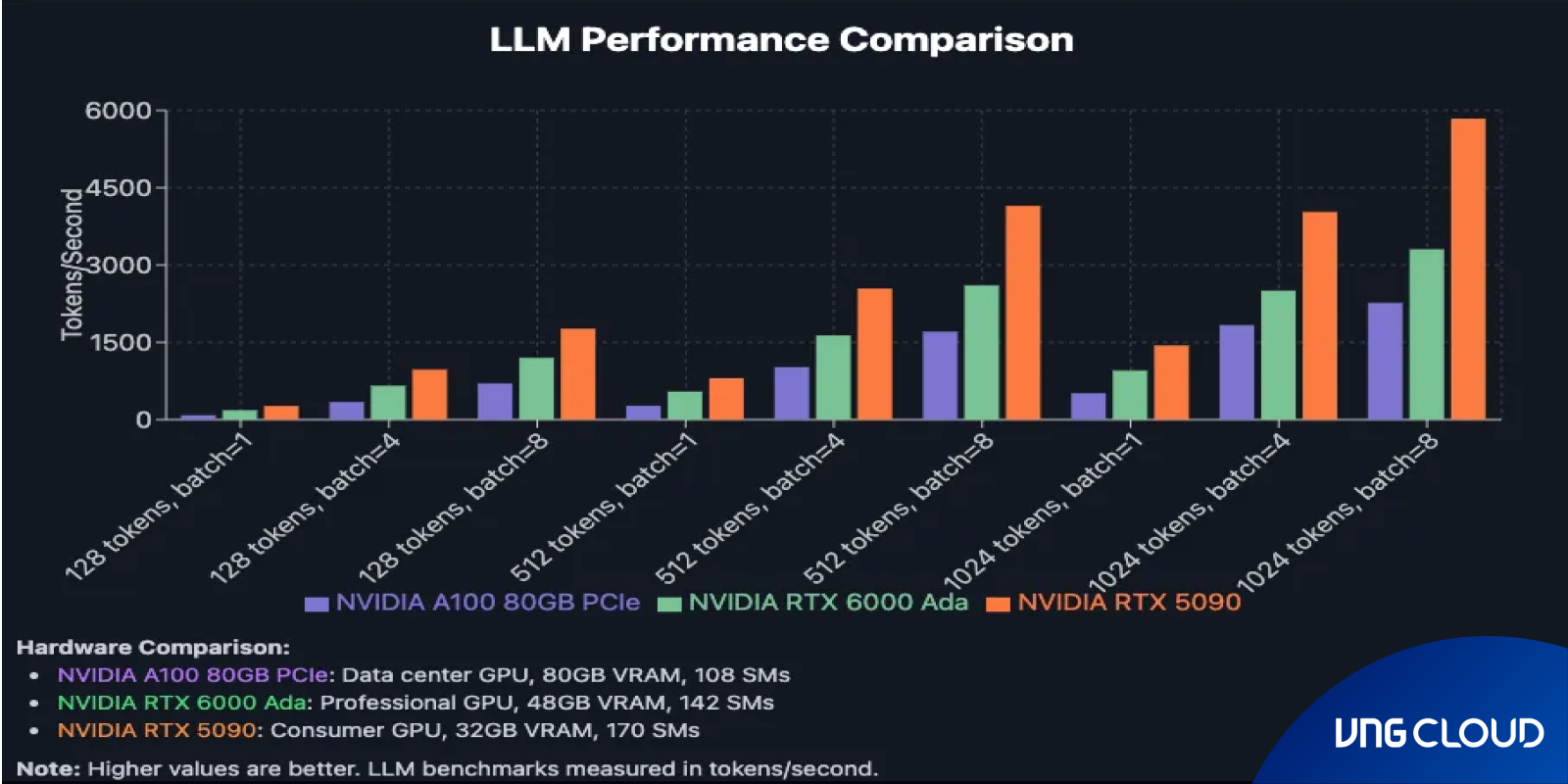
A recent benchmark from Runpod compared the consumer-grade NVIDIA RTX 5090 with the RTX 6000 Ada Generation and the NVIDIA A100 80GB PCIe on Qwen2.5-Coder-7B-Instruct. The findings highlight a surprising performance edge for the RTX 5090.
Despite offering less VRAM (32GB versus 48GB on the RTX 6000 Ada and 80GB on the A100), the RTX 5090 consistently delivered higher throughput across token lengths and batch sizes. At 1,024 tokens with batch size 8, it reached 5,841 tokens/second, outperforming the A100 by 2.6x. This advantage was consistent across multiple configurations.
What Makes the RTX 5090 an LLM Powerhouse?
The NVIDIA RTX 5090 owes its exceptional performance to the new Blackwell architecture, engineered with AI workloads in mind. Featuring 170 Streaming Multiprocessors — compared to 142 on the RTX 6000 Ada and 108 on the A100 — the RTX 5090 delivers significantly greater parallel processing power. While data center GPUs are optimized for reliability and multi-tenancy, the RTX 5090 directs its resources toward maximum computational throughput, making it particularly effective for high-performance inference tasks.
The card demonstrates outstanding efficiency when serving smaller language models at scale. Benchmarks with lightweight models highlight these capabilities: the Qwen2-0.5B model achieves up to 65,000 tokens/second and 250+ requests/second with 1,024 concurrent prompts, while Phi-3-mini-4k-instruct reaches 6,400 tokens/second under the same conditions. This level of performance represents an order-of-magnitude leap over previous-generation hardware for small model deployment.
With such throughput, the RTX 5090 is especially well-suited for chatbots, API endpoints, and real-time services. The only notable limitation is its lower 32GB VRAM compared to certain data center GPUs; however, this can be offset by scaling with additional GPUs as required.

Benchmarking RTX 5090 vs. RTX 4090
To compare the performance of the RTX 5090 and RTX 4090, the VNG Cloud team conducted three benchmark tests: Translation Training, LLM Inference, and LLM Training. These benchmarks provide detailed insights into processing speed, GPU utilization, operating temperature, and real-world training time — offering a comprehensive view of the performance differences between these two flagship GPUs in advanced AI environments.
1. Translation Training
- Number of GPUs: 1.
- Speed: RTX 5090 is about 1.5x faster than RTX 4090.
- GPU utilization: 80%.
- Operating temperature: ~70°C.
The RTX 5090 demonstrates stronger processing power in machine translation training, achieving a 50% speedup over the RTX 4090 while maintaining stable GPU efficiency and relatively cool operating temperatures.
2. Inference LLM
- Model architecture: 14B parameters, optimized with AWQ quantization.
- Number of GPUs: 1.
- Speed: RTX 5090 delivers 2x the performance of RTX 4090.
- GPU utilization: Over 90%.
- Operating temperature: ~80°C.
In complex LLM inference tasks, the RTX 5090 doubles performance thanks to its advanced architecture and optimization techniques, making it ideal for AI applications requiring high speed and accuracy in language inference.
3. LLM Training
- Model architecture: 8B parameters.
- Number of GPUs: 4.
- Speed: RTX 5090 is about 1.3x faster than RTX 4090.
- GPU utilization: Over 90%.
- Operating temperature: ~80°C.
- Training time: 4 days.
When training large-scale LLMs with multiple GPUs, the RTX 5090 continues to maintain a clear speed advantage over the RTX 4090. This results in higher efficiency, better resource optimization, and significantly reduced development time for AI engineers.

The RTX 5090 stands out as the top choice for researchers and AI engineers seeking superior computing power for both training and inference. With speed improvements ranging from 1.3x to 2x over the RTX 4090 across key workloads, stable operating temperatures, and high GPU utilization, the RTX 5090 ensures sustainable performance for the most demanding AI workloads.
Upgrading from RTX 4090 to RTX 5090 means shorter training times, stronger inference capabilities, and fewer technological bottlenecks — unlocking new opportunities for developing next-generation AI solutions.
Are RTX 5090s right for you?
The RTX 5090’s breakthrough performance unlocks new potential across AI applications. Customer service teams can manage thousands of conversations with minimal latency, while content platforms deliver summaries and creative outputs at scale. Data-driven organizations gain real-time insights from information streams, and companies running multiple models can consolidate workloads onto a single GPU — reducing complexity and costs. As slow response times remain a key driver of customer dissatisfaction, the RTX 5090 ensures chatbots and AI services remain fast and reliable.
The new NVIDIA RTX 5090 represents a significant step forward in GPU performance, setting a new standard for AI workloads of every scale. By combining speed, efficiency, and versatility, it enables organizations to accelerate innovation and streamline operations. The RTX 5090 is now available on our portal — Visit today to learn more and start building with the next generation of AI computing.