Natural Language Processing (NLP) is a facet of advanced Artificial Intelligence that empowers computers to comprehend human language. Undertaking projects is a valuable method for gaining proficiency in NLP. This blog introduces the top 7 projects for both beginners and experienced data professionals. Participation in these projects enables leveraging NLP to enhance data analysis and processing.
1. Named Entity Recognition (NER)
Named Entity Recognition (NER) is a fundamental task in Natural Language Processing. Its objective is to identify and categorize entities such as names of individuals, organizations, locations, and dates within a given text.

Objective
The goal of this research is to develop an NER system capable of automatically recognizing and categorizing named entities in text, enabling the extraction of crucial information from unstructured data.
Dataset Overview and Data Preprocessing
For this project, a labeled dataset comprising text with annotated entities will be essential. Widely used datasets for NER encompass CoNLL-2003, OntoNotes, and Open Multilingual Wordnet.
Data Preprocessing: Tokenization
This step involves:
- Tokenizing the text.
- Converting it into numerical representations.
- Addressing any noise or inconsistencies in the annotations.
Queries for Analysis
- Identify and categorize named entities (e.g., people, organizations, locations) in the text.
- Extract relationships between different entities mentioned in the text.
Key Insights and Findings
The NER system accurately recognises and classifies named entities in the given text. It can be applied in information extraction tasks, sentiment analysis, and other NLP applications to derive insights from unstructured data.
2. Machine Translation
Machine Translation is a vital NLP task that automates the translation of text from one language to another, fostering cross-lingual communication and accessibility.

Objective
The goal of Machine Translation is to fluidly translate text from one language to another, facilitating seamless cross-lingual communication and accessibility.
Dataset Overview and Data Preprocessing
This project necessitates parallel corpora, consisting of texts in multiple languages with corresponding translations. Common datasets include WMT, IWSLT, and Multi30k. Data preprocessing involves tokenization, addressing language-specific nuances, and creating input-target pairs for training.
Queries for Analysis
- Translate sentences or documents from the source language to the target language.
- Evaluate the translation quality using metrics like BLEU and METEOR.
Key Insights and Findings
The machine translation system is expected to generate reliable translations across multiple languages, fostering cross-cultural communication and enhancing global accessibility to information.
3. Text Summarization
Text Summarization is a vital task in Natural Language Processing, encompassing the creation of concise and coherent summaries for longer texts. This process facilitates rapid information retrieval and comprehension, proving invaluable when dealing with substantial volumes of textual data.

Objective
The objective of this project is to develop an abstractive or extractive text summarization model capable of producing informative and concise summaries from lengthy text documents.
Dataset Overview and Data Preprocessing
This project requires a dataset containing articles or documents with human-generated summaries. Data preprocessing involves text tokenization, punctuation handling, and the creation of input-target pairs for training.
Queries for Analysis
- Generate summaries for long articles or documents.
- Evaluate the quality of generated summaries using ROUGE and BLEU metrics.
Key Insights and Findings
The text summarization model is anticipated to effectively produce concise and coherent summaries, thereby improving the efficiency of information retrieval and enhancing the user experience when dealing with extensive textual content.
4. Text Correction and Spell Checking
Projects in Text Correction and Spell Checking endeavor to create algorithms that automatically rectify spelling and grammatical errors in textual data. This enhances the accuracy and readability of written content.

Objective
The goal of this project is to construct a spell-checking and text-correction model to elevate the quality of written content and ensure effective communication.
Dataset Overview and Data Preprocessing
This project necessitates a dataset comprising text with misspelled words and their corresponding corrected versions. Data preprocessing involves addressing capitalization, punctuation, and special characters.
Queries for Analysis
- Detect and correct spelling errors in a given text.
- Suggest appropriate replacements for erroneous words based on context.
Key Insights and Findings
The text correction model is expected to precisely identify and rectify spelling and grammatical errors, significantly enhancing the quality of written content and minimizing misunderstandings.
5. Sentiment Analysis
Sentiment Analysis stands as a crucial task in NLP, determining the sentiment conveyed in a text - whether it is positive, negative, or neutral. It plays a pivotal role in analyzing customer feedback, market sentiments, and monitoring social media.

Objective
The goal of this project is to create a sentiment analysis model capable of categorizing text into sentiment categories and extracting insights from textual data.
Dataset Overview and Data Preprocessing
Training the sentiment analysis model necessitates a labeled dataset of text data with corresponding sentiment labels. Data preprocessing involves tasks such as text cleaning, tokenization, and encoding.
Queries for Analysis
- Analyze social media posts or product reviews to determine sentiment.
- Monitor changes in sentiment over time for specific products or topics.
Key Insights and Findings
The sentiment analysis model is anticipated to empower businesses in effectively understanding customer opinions and sentiments, facilitating data-driven decisions, and enhancing overall customer satisfaction.
6. Text Annotation and Data Labeling
Tasks related to Text Annotation and Data Labeling are essential in NLP projects, as they encompass the process of labeling text data to train supervised machine learning models. This step is crucial to guarantee the accuracy and quality of NLP models.
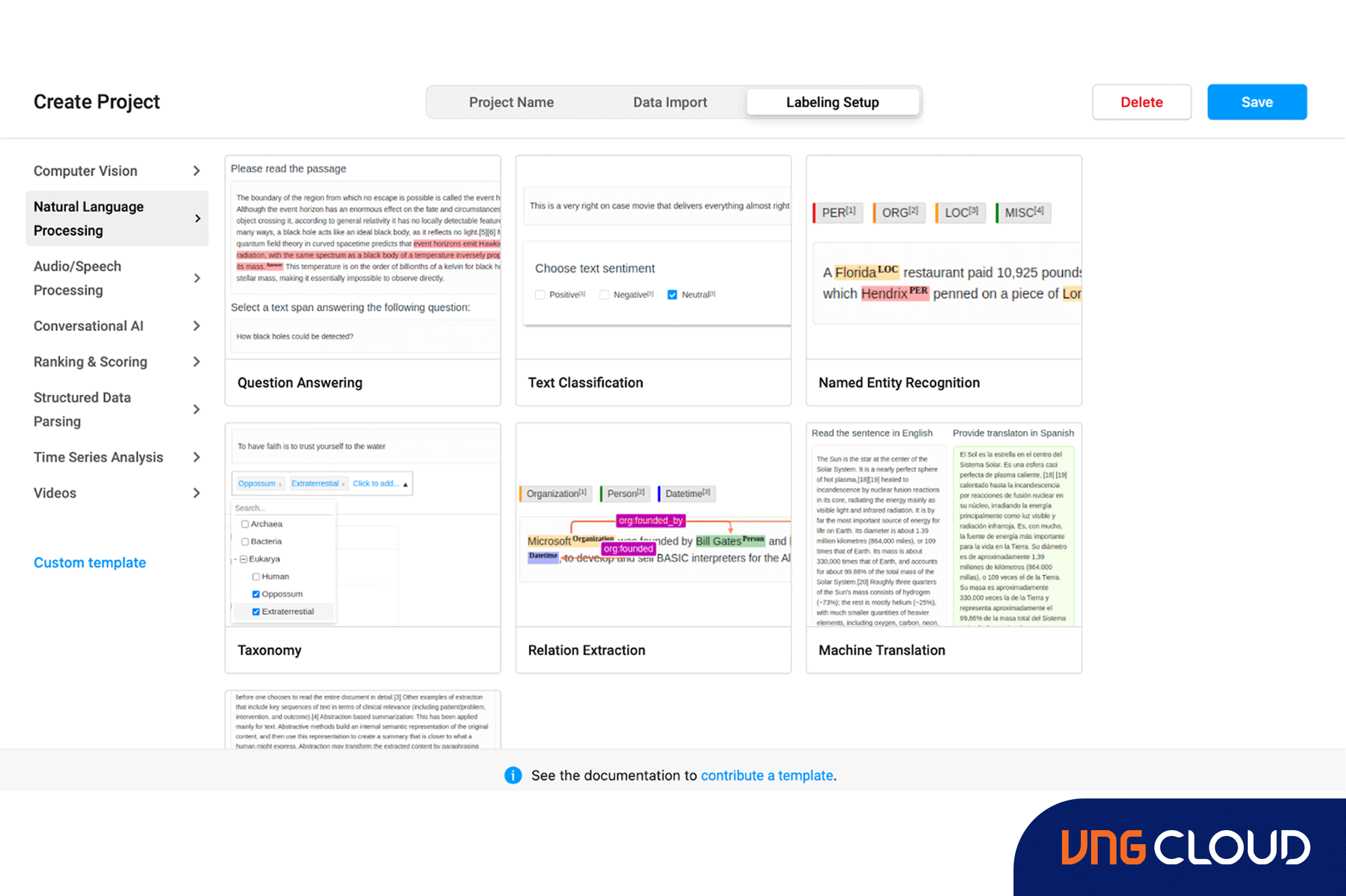
Objective
This project aims to create an annotation tool or application that effectively enables human annotators to label and annotate text data for NLP tasks.
Dataset Overview and Data Preprocessing
The project necessitates a dataset of text data requiring annotations. Data preprocessing involves developing a user-friendly annotator interface and ensuring consistency and quality control.
Queries for Analysis
- Provide a platform for human annotators to label entities, sentiments, or other relevant information in the text.
- Ensure consistency and quality of annotations through validation and review mechanisms.
Key Insights and Findings
The annotation tool is anticipated to streamline the data labeling process, facilitating faster NLP model development and ensuring the accuracy of labeled data for improved model performance.
7. Deepfake Detection
The emergence of deepfake technology has heightened concerns about the authenticity and credibility of multimedia content, underscoring the critical nature of Deepfake Detection as an essential NLP task. Deepfakes involve manipulated videos or audio that can deceive viewers, presenting a potential risk for the dissemination of false information.

Objective
This project aims to develop a deep learning-based model capable of identifying and flagging deepfake videos and audio, safeguarding media integrity, and preventing misinformation.
Dataset Overview and Data Preprocessing
Training the deepfake detection model requires a dataset containing both deepfake and real videos and audio. Data preprocessing involves preparing the data for training by converting videos into frames or extracting audio features.
Queries for Analysis
- Detect and classify deepfake videos or audio.
- Evaluate the model's performance using precision, recall, and F1-score metrics.
Key Insights and Findings
The deepfake detection model is expected to assist in identifying manipulated multimedia content, preserving the authenticity of media sources, and protecting against potential misuse and misinformation.
Final Thoughts
In part 1 of our exploration into top-notch NLP projects in 2024, we've covered a spectrum of applications. Engaging with these projects provides a valuable avenue for both beginners and seasoned data professionals to enhance their proficiency in NLP, contributing to more adept data analysis and processing. Stay tuned for part 2, where we'll delve deeper into more NLP projects in 2024 in the upcoming article.
Do not forget to subscribe to VNG Cloud for deeper insights into AI, Machine Learning, and Natural Language Processing in the cloud. If you're keen on exploring cloud solutions for your business's NLP applications, feel free to reach out to us.