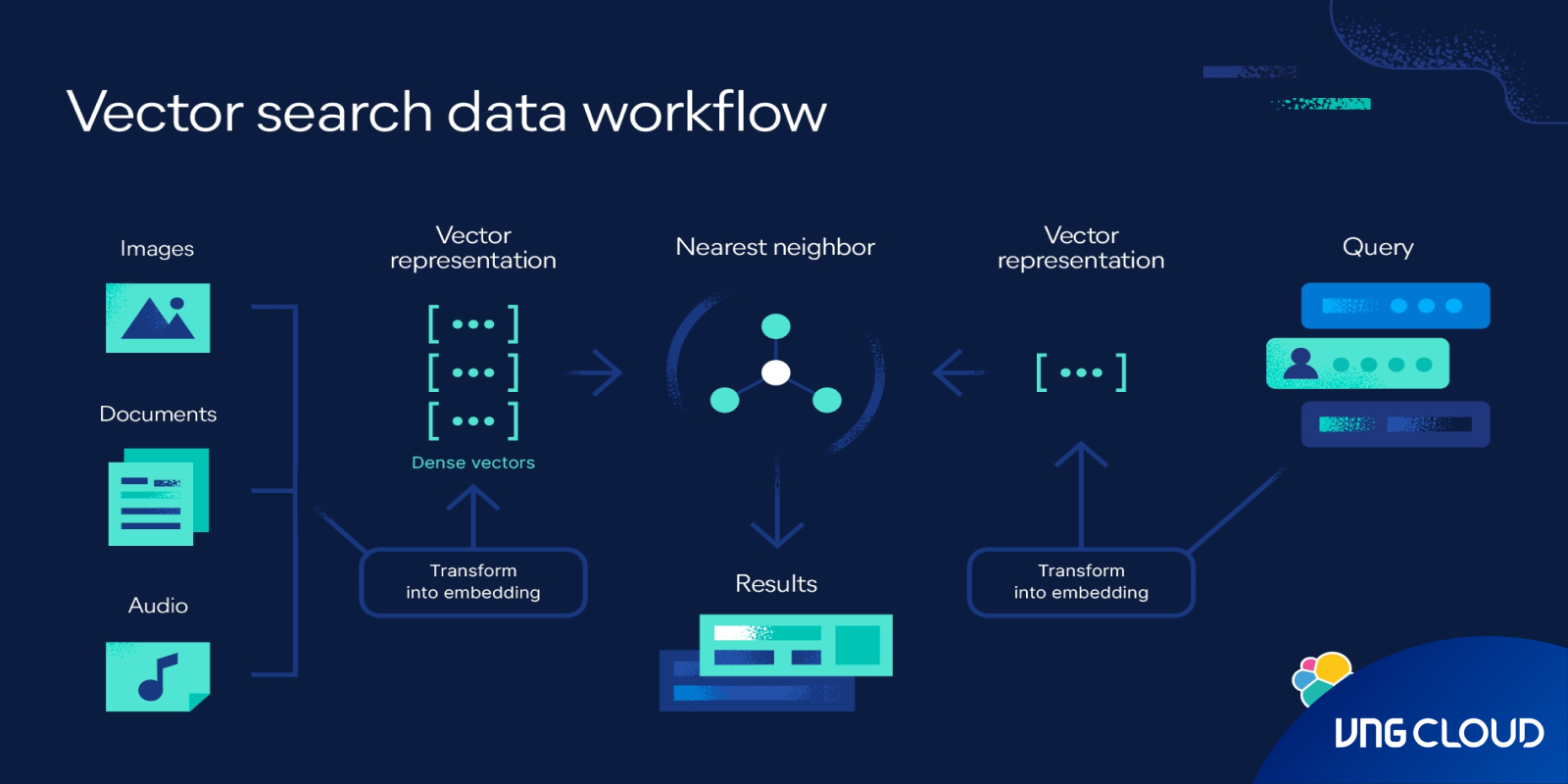
In today’s digital landscape, users expect search to understand context and intent. While conventional search engines rely on word-to-word matching, they often fail to capture the semantic meaning behind a query. For example, a phrase like 'a quiet spot to read a book' might return results like bookshelves or lamps, rather than the intended comfy place.
OpenSearch addresses this gap with machine learning and embedding models, which convert language into high-dimensional vectors - positioned in space so that semantically similar content appears closer together. This enables OpenSearch to perform k-nearest neighbor (k-NN) searches that retrieve results based on meaning rather than literal word matches.
With native vector capabilities, OpenSearch functions as a full-fledged vector database - allowing businesses to integrate semantic search, recommendation engines, and Retrieval-Augmented Generation (RAG) into their platforms. It supports multimodal data, including text and images, enabling rich and nuanced discovery experiences across complex datasets. For developers and enterprises looking to deploy AI-ready infrastructure within a secure and locally hosted environment, vDB OpenSearch of VNG Cloud offers the tools to scale, customize, and innovate - while maintaining full control over data and compliance standards.
Using OpenSearch Service as a vector database
With the vector database capabilities, businesses can unlock advanced search experiences through technologies like semantic search, Retrieval Augmented Generation (RAG) with large language models (LLMs), recommendation engines, and media-rich search.
Semantic search
Semantic search enhances result relevance by using language-based embeddings to understand the context and meaning behind a user's query. Instead of relying on exact keyword matches, semantic search allows users to type natural language prompts - like “a comfy place to read a book” - and receive results that align with their intent, such as libraries or cafes, rather than unrelated results. By encoding both queries and documents into high-dimensional vectors, OpenSearch enables precise similarity searches through k-nearest neighbor (k-NN) indexing.
This vector-based approach consistently delivers improved search performance, as it captures the semantics of user input and matches it to the most contextually relevant content. Powered by modern ML models and built for enterprise scalability, OpenSearch helps organizations build intelligent search applications that feel intuitive, personalized, and AI-driven.
Retrieval Augmented Generation with LLMs
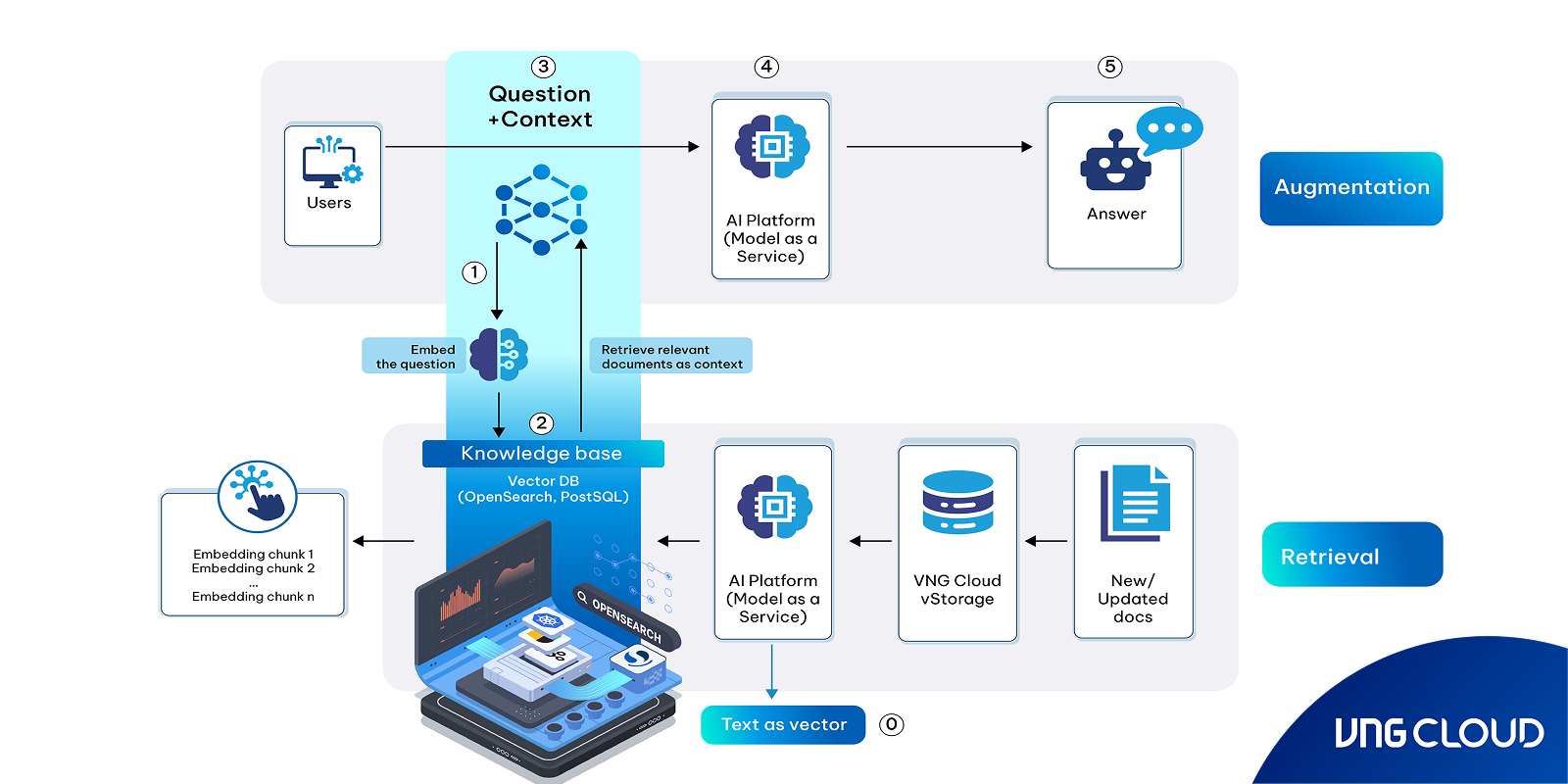
RAG is an effective method for building reliable AI-powered chatbots and search experiences using generative large language models (LLMs) such as GPT-based systems. As LLMs become increasingly integrated into enterprise applications, developers are seeking ways to make them more trustworthy and domain-aware. RAG addresses a key limitation of generative models—the tendency to hallucinate or produce factually incorrect information—by grounding their responses in real data from an external knowledge base.
In a typical RAG workflow, user queries are first embedded into vector representations and used to search a vector database. This database is preloaded with semantically encoded knowledge content - such as product manuals, customer support documents, or internal business guidelines. The most relevant content is retrieved and passed to the LLM, which then generates a natural, conversational response based on that context. OpenSearch is used as the underlying vector database to manage and query vectorized knowledge efficiently.
This approach enables businesses to deliver intelligent Q&A and chatbot experiences that are not only conversational but also accurate and up-to-date. Whether you’re building AI assistants for technical support, healthcare, legal advisory, or any domain requiring factual accuracy, RAG grounds the model on facts to minimize ‘hallucinations’ by complementing the generative model with a knowledge base.
Recommendation engine
Recommendation systems are a key part of enhancing the search experience, especially in ecommerce and content platforms. Features like “more like this” or “customers who viewed this also liked” help personalize the user journey and increase engagement and conversions. To build these systems, engineers often rely on advanced techniques such as deep neural network (DNN)–based recommendation algorithms, including architectures like the Two-tower model or YoutubeDNN.
In these setups, trained embedding models convert products or content into vector representations within a multi-dimensional space. Items that are similar—based on purchase behavior, user interactions, or co-rating patterns—are positioned closer together in that space. By calculating the vector similarity between a user’s profile (also represented as a vector) and product vectors stored in a vector database, the system can surface highly relevant recommendations.
With OpenSearch used as the vector database, this recommendation workflow can be executed efficiently at scale. OpenSearch's k-NN capabilities allow fast and accurate similarity searches, enabling businesses to deliver real-time, personalized suggestions that feel intuitive and contextually appropriate to each user.
Media Search
Media search allows users to interact with search systems using rich media inputs such as images, audio, or video instead of just text. Its implementation is similar to semantic search - vector embeddings are generated for media files and queries, enabling similarity matching based on content rather than keywords. The key difference lies in the models used: for media search, deep neural networks specialized in computer vision, such as Convolutional Neural Networks (CNNs) like ResNet, are employed to transform images into vector representations.

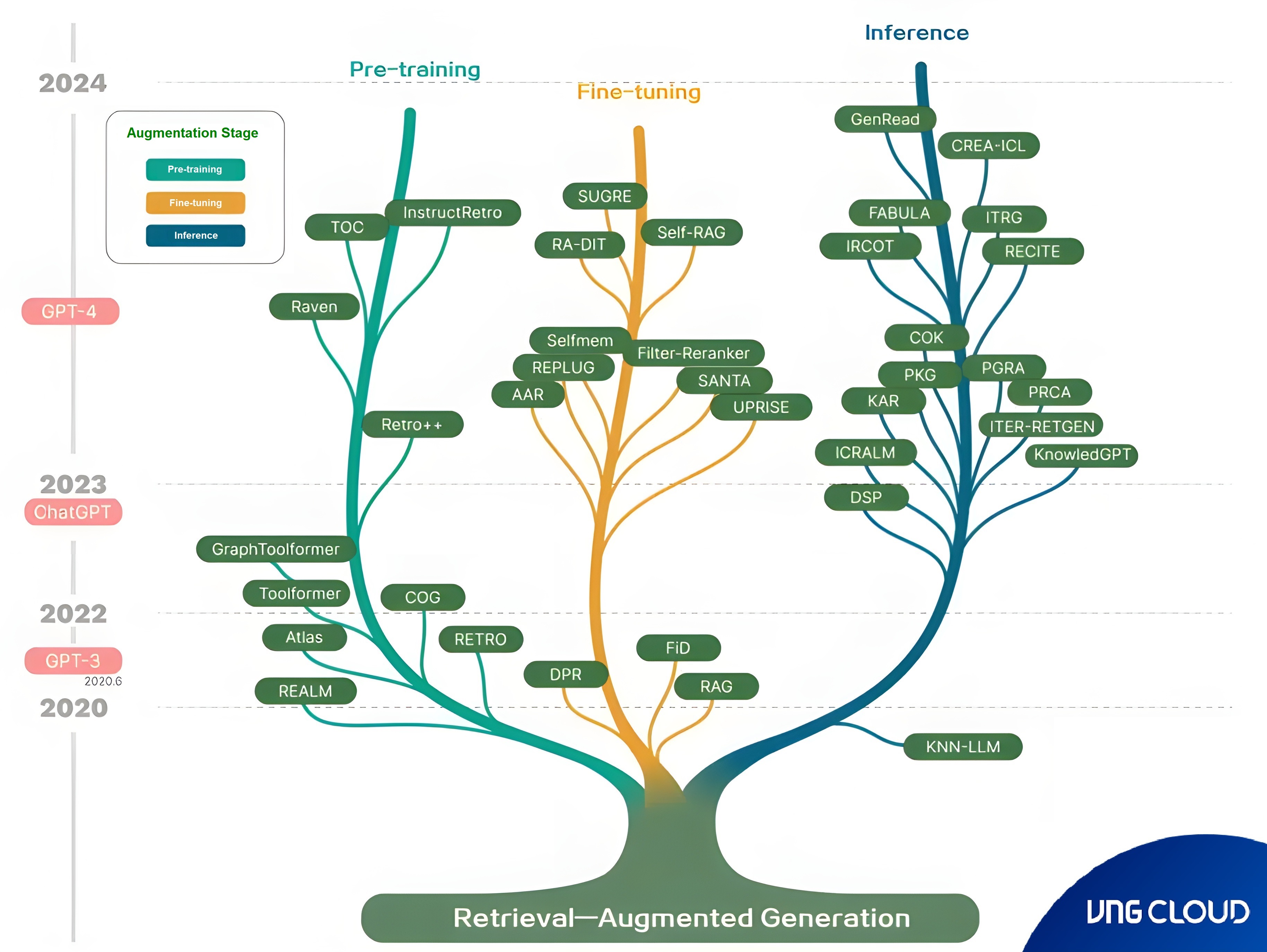
Approximate and Exact Nearest-Neighbor Search in OpenSearch
The OpenSearch k-NN plugin offers 03 methods for nearest-neighbor search:
- Approximate k-NN: Uses algorithms like HNSW and IVF to quickly find approximate neighbors, trading some accuracy for speed and scalability. Ideal for large datasets needing low-latency searches but not suitable when heavy filtering is required.
- Score Script (Exact k-NN): Executes a brute-force search over a subset of vectors, offering precise results. Best for smaller datasets or searches requiring pre-filtering, though it can be slow on large indexes.
- Painless Extensions (Exact k-NN): Similar to score script but enables more complex, customizable scoring. It also supports pre-filtering but is slightly slower.
Vector Search Algorithms:
- Exact k-NN works well for small datasets but struggles with scaling on high-dimensional data.
- Approximate Nearest Neighbor (ANN) methods improve performance on large datasets by optimizing index structure and reducing dimensions.
Implemented ANN Algorithms in OpenSearch:
- HNSW (Hierarchical Navigable Small Worlds): Builds a graph to efficiently traverse and find neighbors by visiting vectors close to the query.
- IVF (Inverted File System): Organizes vectors into buckets based on similarity to representative vectors, reducing search time by querying only relevant buckets.
Advantage of OpenSearch as a vector database
When you use OpenSearch as a vector database, you can leverage its built-in strengths in usability, scalability, availability, interoperability, and security. More importantly, you can utilize OpenSearch’s advanced search capabilities to enhance the overall search experience. For example, you can apply Learning to Rank to incorporate user clickthrough behavior data and improve search relevance. OpenSearch also allows you to combine text search and vector search, enabling document retrieval based on both keyword matching and semantic similarity. Additionally, you can use other fields in the index to filter documents and further refine relevance. For more advanced scenarios, you can implement a hybrid scoring model that blends OpenSearch’s text-based relevance score, computed using the Okapi BM25 function, with its vector search score to deliver better-ranked search results.
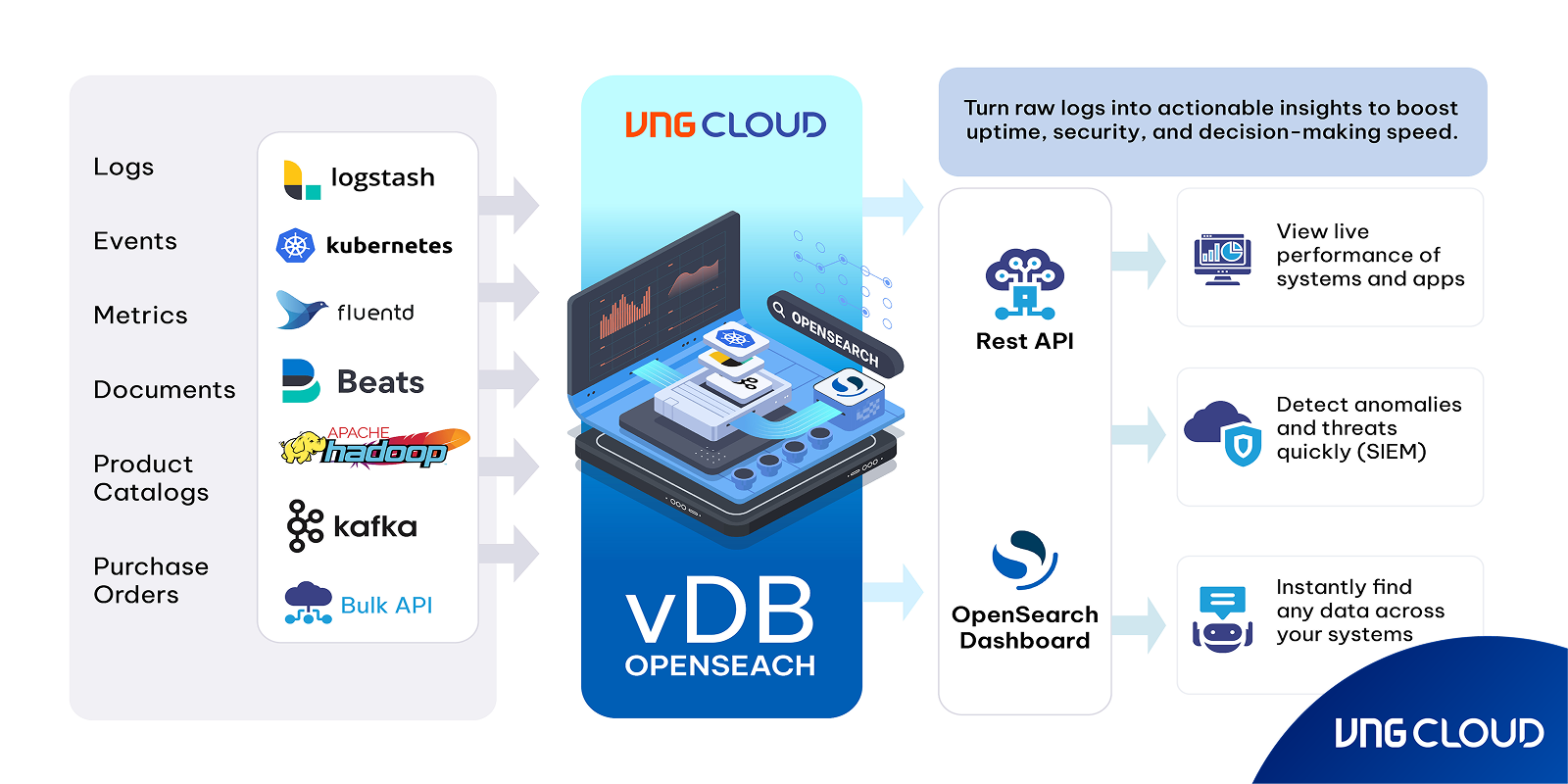
vDB OpenSearch of VNG Cloud is a powerful solution for distributed data storage and querying, designed to support search, log analytics, system monitoring, and Big Data processing. Now, you can deploy OpenSearch as a Vector Database on VNG Cloud, thanks to the built-in k-NN Plugin, enabling approximate nearest neighbor (k-NN) search on vector embeddings - the key to powering AI/ML applications like Semantic Search, Recommendation Systems, NLP Applications, and AI Vector Indexing.
OpenSearch Cluster stands out with its easy setup and management, seamless log ingestion from multiple sources, scalable architecture, secure access control, and flexible plugin support for advanced search capabilities — all with transparent pricing to help you manage your budget effectively. Launch your OpenSearch Cluster now and unlock the future of smart search.