Minimizing system downtime is crucial for businesses as it can result in significant costs. Fortunately, there are effective strategies to mitigate this issue and its negative impact on your organization. Discover our 10 tips to prevent server downtime and ensure uninterrupted operations for your business.
The truth is that the effectiveness of IT systems relies heavily on their stability. No matter how great a service may be, its value diminishes if users cannot access it. This emphasizes the significance of prioritizing stability during the design and development stages.
The average cost of downtime is estimated to be $5,600 per minute, according to a 2014 study by Gartner. However, this figure can vary significantly based on factors such as company size and industry vertical. An Avaya report from the same year found that averages ranged from $2,300 to $9,000 per minute. Furthermore, a report by the Ponemon Institute in 2016 raises Gartner's average to nearly $9,000 per minute. It's important to note that these figures have been increasing since 2014.
Unforeseen periods of downtime can lead to significant financial implications for your company, including lost productivity, revenue, and additional expenses. While downtime costs vary across industries and are typically higher for larger corporations, smaller businesses also face financial strains due to limited resources. Therefore, ensuring stability is always a crucial and costly consideration. It comes as no surprise that availability is frequently emphasized by IT Managers as a vital aspect when evaluating network services.
IT Managers strive to minimize downtime and ensure smooth operations within their companies. If you find yourself concerned about this issue, we - VNG Cloud, as professional cloud service provider for enterprises, offer the following tips based on our expertise and research.
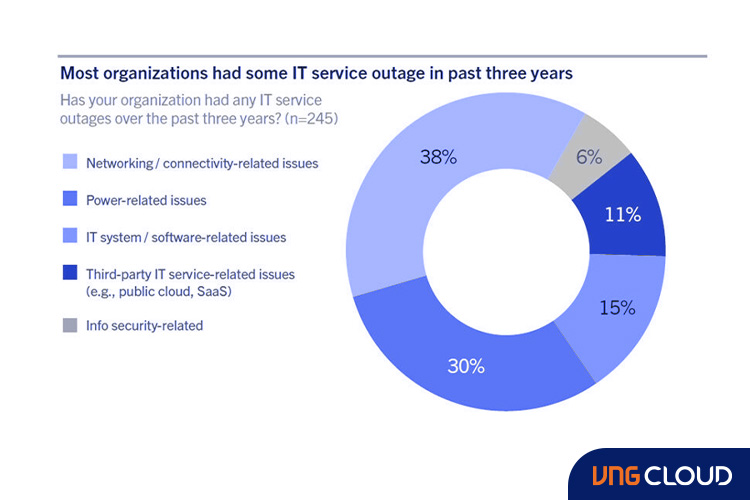
What causes system downtime?
Let's begin by addressing some of the common causes of system downtime that you should be aware of:
- Power grid outages and network outages: Servers require a steady power supply, and any disruption in the power grid or network connectivity can lead to downtime.
- Criminal activity: Cyber attacks, such as Distributed Denial of Service (DDoS) attacks or data breaches, can compromise your system's security and result in significant downtime.
- Hardware failures: Despite their reliability, computer hardware can experience failures over time. It is essential to have contingency plans in place to handle hardware failures and minimize their impact on your system.
- Resource overload: Insufficient resources and architectural bottlenecks can strain your system's performance, especially during periods of high traffic or rapid user growth. This can lead to stability issues and even server failures.
- Human errors: Mistakes such as misconfigurations or deployment failures by individuals involved in system management can cause downtime and disrupt normal operations.
- Improperly designed architecture: Inadequate system architecture planning and design can result in poor efficiency and scalability. The system may function adequately under low load but struggle to perform under high traffic conditions.
By understanding these potential causes, you can take proactive steps to address them and mitigate the risk of system downtime.
10 Strategies for IT Managers to Minimize System Downtime
1. Cloud adoption
Cloud platforms such as AWS, Azure, or VNG Cloud are highly reliable options for ensuring system stability. These professional-grade services often provide explicit uptime guarantees. By engaging cloud service providers, you can benefit from their expertise in designing robust architectures and implementing safeguards to optimize system performance.
While no solution can guarantee absolute certainty, cloud service providers typically offer Service Level Agreements (SLAs) with availability values surpassing 90% or more. This level of reliability demonstrates the commitment of cloud providers to minimize downtime and ensure continuous access to your systems.
Cloud providers offer a wide range of services, including queues, messaging platforms, and databases, which come with built-in high availability (HA) and replication features. These services are maintained by the providers themselves, reducing the responsibility for system uptime on your IT team's side.
By leveraging the cloud, you can mitigate potential downtime issues effectively. The best part is that you can focus on your core responsibilities, while experienced specialists, including the cloud provider and cloud developers, ensure the stability of your system.
Moreover, the cloud offers numerous other advantages for your company. With a cloud platform, you have the flexibility to schedule automatic upscaling of your system as needed. For instance, if you anticipate peak traffic during weekend afternoons, you can schedule additional nodes to be added to your Kubernetes cluster, allowing for seamless handling of increased user load. After the peak period, the environment can be scaled back down to optimize costs.
While the cloud provides significant benefits, it is not a foolproof solution for achieving infinite uptime. Proper planning of your system architecture, utilizing the appropriate cloud components, and acknowledging that even major cloud providers may experience occasional downtime events are crucial considerations for your businesses.

2. Using multi-instances
To keep your application running smoothly, utilize multiple instances using containers like Docker with orchestration software such as Kubernetes or OpenShift. Clustering orchestrators across instances allows for horizontal scalability and ensures system availability, even during infrastructure failures.
For example, an instance of Kubernetes can be set up on the VNG Cloud with two nodes. By configuring an autoscaling trigger to add an additional node when CPU pressure exceeds 75% for a certain duration, the system can scale accordingly. With Kubernetes, it is also possible to spawn more application pods based on specific metrics such as requests per minute.
Having multiple nodes in your cluster ensures the availability of your application even if a part of the cluster fails. Kubernetes strives to distribute pods evenly across the cluster's instances.
Using multiple instances and orchestration provides the advantage of zero-downtime deployments. With strategies like Rolling Update or Blue-Green deployment, you can safely introduce a new version of your application while ensuring that at least one instance of your service remains functional. Additionally, if the deployment of the new version encounters issues, an orchestrator allows for seamless rollback to the previous version that is still operational.
Containers, orchestrators, and a multi-instance approach often lead to the adoption of microservices architecture. However, it's important to note that this architectural style may not be the ideal solution for every situation. While it offers benefits such as isolation and resilience, it can also introduce challenges like transaction management and increased complexity for implementing new functionalities. On the positive side, a well-implemented microservices architecture ensures that downtime in one part of the system does not impact the functionality of other independent components.
3. Improving deployments with CI/CD
Implementing CI/CD (Continuous Integration and Continuous Delivery) is a powerful approach to improve deployments and minimize the risks associated with them, thereby reducing system downtime. With CI/CD practices, you can automate the release of updates and streamline the testing process, including new feature testing and regression testing for existing system components. You can even achieve seamless deployments, enabling updates to be pushed directly to production without causing any downtime. CI/CD allows you to make deployment processes efficient and reliable, ensuring smooth and uninterrupted system operations.
Automating deployment scripts serves as a defense against human errors, preventing common mistakes like missing deployment steps or errors during the process. With automated scripts, every deployment follows a consistent and reliable procedure. Furthermore, monitoring the deployment frequency, one of the key metrics in the DORA framework, helps prevent system downtime. By tracking the successful deployment of code changes to production, teams can proactively identify and resolve potential issues before they lead to downtime, promoting a more stable and resilient system.
4. Regular backups and disaster recovery
Backups are essential for easier and quicker system recovery during crises. Maintaining at least three copies of your data, including one stored outside your regular infrastructure, is recommended. Regular backups minimize the impact of system downtime and should be integrated into your CI/CD pipeline. The frequency of backups directly influences the Recovery Time Objective (RTO) for system recovery. While constant replication reduces data loss, periodic backups become crucial in cases of data corruption. Striking a balance between continuous replication and regular backups ensures comprehensive data protection.
Combining cloud and on-premise platforms for backup environments is a reliable way to enhance system uptime. By utilizing cold or warm copies of your production environment on a different platform, such as placing the main environment on VNG Cloud and the backup copy on-premise, you can mitigate issues and reduce dependency on the cloud provider's SLA. Implementing traffic routing with domain-level health checks allows for seamless redirection of traffic to the backup platform in case of cloud platform issues. Despite the cost and constant data replication requirements, this approach ensures an exceptional level of uptime and enables your application to remain fully functional even during data center outages.
Despite your best efforts, downtime events are inevitable, as certain factors like natural disasters are beyond your control. Therefore, it is essential to establish well-defined procedures to handle such situations. Ensuring that your staff is knowledgeable about responding to system outages, including the necessary steps to take and whom to contact, is crucial. By being prepared and having a solid plan in place, you can not only save significant costs but also avoid unnecessary stress and complications.

5. Load testing
Load testing is essential for assessing the performance of your core IT systems and ensuring they can handle the expected workload during typical usage scenarios. It also helps you prepare for potential crisis situations, such as partial resource failures.
During load testing, you can identify bottlenecks and determine the performance limit of your system. Optimizing these bottlenecks through techniques like algorithm optimization, caching, or architectural and configuration changes is crucial. The earlier you identify potential issues, the lower the risk of failures. You should regularly conduct load tests and promptly address any identified issues is highly recommended to maintain system stability and reliability.
6. Ensuring proper scalability
It is important to design your system with scalability in mind, allowing for seamless expansion and continuous operation as your company grows. Incorporating forward-thinking technologies can greatly reduce the risk of unnecessary system downtime. Cloud configuration is a popular approach for achieving scalability.
When developing algorithms and functions, you should consider the system's ability to handle increasing data volumes. While certain algorithms may work well with small datasets or limited users, they can become inefficient and slow when faced with thousands of concurrent users. Using algorithms with poor complexity factors can lead to crashes and system failures. Therefore, it is vital to prioritize algorithms that can effectively process large amounts of data without compromising system performance.
7. Choosing your tech stack well
Relying on too many systems and technologies can lead to disasters, causing bugs, glitches, and complexity. It is recommended to use compatible solutions, preferably from the same vendor, to avoid unnecessary complications.
For example, when storing files in your system, using a BLOB in the database can result in slow queries and larger table sizes. Storing files directly on a hard drive is a better option, while caching them in a Common Data Environment (CDE) is the best approach. The CDE offloads traffic from your application to the cloud provider's infrastructure, ensuring faster transfers and lighter queries.
8. Monitoring and updating hardware
Computer hardware, like any electronic device, has a limited lifespan and can become outdated over time. Thus, it's crucial to prioritize system upgrades to ensure optimal performance and compatibility with new software solutions.
Regular monitoring of your equipment, ensuring cleanliness, stable power supply, and preventing overheating are essential maintenance practices. It's equally important to recognize when it's time to retire an old server and invest in a new machine. Delaying this decision can lead to serious consequences. Alternatively, you can alleviate the burden of hardware maintenance by opting for a cloud solution provided by a reliable cloud provider.

9. Meticulous maintenance
Creating software is just the beginning; proper maintenance is essential for smooth and issue-free system operation. Maintenance should be seen as a continuous process that requires dedicated attention for organizations. It encompasses various activities such as bug fixes, security updates, performance optimizations, and enhancements. By prioritizing meticulous maintenance practices, you can ensure the longevity and reliability of your software solutions. Regularly review and update your maintenance strategies to keep pace with evolving technology and industry best practices.
10. System security
The significance of cybersecurity cannot be underestimated, and neglecting it can have detrimental consequences for companies. Addressing cybersecurity involves resolving various security issues. However, one additional measure that can significantly enhance security is conducting a security audit performed by a specialized third-party company. This audit not only raises cybersecurity awareness within your team but also uncovers potential vulnerabilities that may have gone unnoticed.
Failure to address security issues can lead to data breaches, which can have severe legal and reputational implications, as well as data corruption and system overloads. To mitigate these risks, it is crucial to promptly address and patch any vulnerabilities identified during the security audit process.
Effective cybersecurity involves more than just bug removal; it requires proactive measures to prevent breaches. Implementing mechanisms such as firewalls and blacklists is crucial to thwart potential attacks. Services like WAF offer features that block suspicious requests, including those associated with DDoS attacks and SQL injections. When detected, these services promptly block the corresponding IP addresses and can trigger alerts via email or SMS gateways.
To further enhance security, automated penetration testing can be employed as a preventive measure. By simulating hacking attempts on your own systems, you can identify potential vulnerabilities. If the automated system can bypass your security measures, it indicates that malicious hackers may also exploit these weaknesses. Promptly addressing and patching these vulnerabilities is essential to fortify your defenses.
FAQs about system downtime
1. What is system downtime?
System downtime refers to a period when an IT system is inaccessible to users due to various reasons. Planned downtime is a scheduled part of the system's regular maintenance or updates, while unplanned downtime occurs unexpectedly due to issues that require prompt resolution to minimize costs and disruptions.
2. What causes system downtime?
System downtime can be caused by hardware failures, human errors, power outages, cyberattacks, software issues, network failures, natural disasters, scheduled maintenance, capacity limitations, and environmental factors.
3. How to calculate system downtime?
To calculate your yearly uptime percentage, divide the total number of hours your system ran without problems by the number of hours in a year (typically 8760), then multiply the result by 100. The downtime percentage can be obtained by subtracting the uptime percentage from 100%. For instance, if a service experienced 20 hours of unavailability in a year, the uptime value would be 99.78% and the downtime percentage would be 0.22%.